Las primeras CPU fueron diseñadas a la medida como parte de una computadora más grande, generalmente una computadora única en su especie. Sin embargo, este costoso método de diseñar los CPU a la medida, para una aplicación particular, ha desaparecido en gran parte y se ha sustituido por el desarrollo de clases de procesadores baratos y estandarizados adaptados para uno o muchos propósitos. Esta tendencia de estandarización comenzó generalmente en la era de los
Transistores discretos,
computadoras centrales, y
Microcomputadoras, y fue acelerada rápidamente con la popularización del
Circuito integrado (IC), éste ha permitido que sean diseñados y fabricados CPU más complejos en espacios pequeños (en la orden de
Milímetros). Tanto la miniaturización como la estandarización de los CPU han aumentado la presencia de estos dispositivos digitales en la vida moderna mucho más allá de las aplicaciones limitadas de máquinas de computación dedicadas. Los microprocesadores modernos aparecen en todo, desde
Automóviles,
Televisores,
Neveras,
Calculadoras,
aviones, hasta teléfonos móviles o celulares,
Juguetes, entre otros.
Por otro lado, mientras que los tubos de vacío no sufren del rebote de contacto, éstos deben calentarse antes de llegar a estar completamente operacionales y eventualmente fallan y dejan de funcionar por completo. Generalmente, cuando un tubo ha fallado, el CPU tendría que ser diagnosticado para localizar el componente que falla para que pueda ser reemplazado. Por lo tanto, los primeros computadores electrónicos, (basados en tubos de vacío), generalmente eran más rápidas pero menos confiables que las computadoras electromecánicas, (basadas en relés).
Las computadoras de tubo, como el
EDVAC, tendieron en tener un promedio de ocho horas entre fallas, mientras que las computadoras de relés, (anteriores y más lentas), como el
Harvard Mark I, fallaban muy raramente . Al final, los CPU basados en tubo llegaron a ser dominantes porque las significativas ventajas de velocidad producidas generalmente pesaban más que los problemas de confiabilidad. La mayor parte de estos tempranos CPU síncronos corrían en
frecuencias de reloj bajas comparadas con los modernos diseños microelectrónicos, (ver más abajo para una exposición sobre la frecuencia de reloj). Eran muy comunes en este tiempo las frecuencias de la señal del
reloj con un rango desde 100
kHz hasta 4
MHz, limitado en gran parte por la velocidad de los dispositivos de conmutación con los que fueron construidos.
Operación del CPU
La operación fundamental de la mayoría de los CPU, es ejecutar una secuencia de instrucciones almacenadas llamadas "programa". El programa es representado por una serie de números que se mantentienen en una cierta clase de memoria de computador. Hay cuatro pasos que casi todos los CPU de
Arquitectura de von Neumann usan en su operación: fetch, decode, execute, y writeback, (leer, decodificar, ejecutar, y escribir).
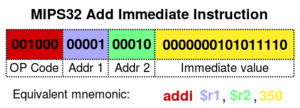
Mips32 addi.svg
El primer paso, leer (fetch), implica el recuperar una
Instrucción, (que es representada por un número o una secuencia de números), de la memoria de programa. La localización en la memoria del programa es determinada por un
Contador de programa (PC), que almacena un número que identifica la posición actual en el programa. En otras palabras, el contador de programa indica al CPU, el lugar de la instrucción en el programa actual. Después de que se lee una instrucción, el Contador de Programa es incrementado por la longitud de la palabra de instrucción en términos de unidades de memoria. Frecuentemente la instrucción a ser leída debe ser recuperada de memoria relativamente lenta, haciendo detener al CPU mientras espera que la instrucción sea retornada. Este problema es tratado en procesadores modernos en gran parte por los cachés y las arquitecturas
Pipeline (ver abajo).
La instrucción que el CPU lee desde la memoria es usada para determinar qué deberá hacer el CPU. En el paso de decodificación, la instrucción es dividida en partes que tienen significado para otras unidades del CPU. La manera en que el valor de la instrucción numérica es interpretado está definida por la arquitectura del
Conjunto de instrucciones (el ISA) del CPU. A menudo, un grupo de números en la instrucción, llamados
Opcode, indica qué operación realizar. Las partes restantes del número usualmente proporcionan información requerida para esa instrucción, como por ejemplo, operandos para una operación de
Adición.
Tales operandos se pueden dar como un valor constante (llamado valor inmediato), o como un lugar para localizar un valor, que según lo determinado por algún
Modo de dirección, puede ser un
registro o una
Dirección de memoria. En diseños más viejos las unidades del CPU responsables de decodificar la instrucción eran dispositivos de hardware fijos. Sin embargo, en CPUs e ISAs más abstractos y complicados, es frecuentemente usado un
Microprograma para ayudar a traducir instrucciones en varias señales de configuración para el CPU. Este microprograma es a veces reescribible de tal manera que puede ser modificado para cambiar la manera en que el CPU decodifica instrucciones incluso después de que haya sido fabricado.

Diagrama del CPU
Después de los pasos de lectura y decodificación, es llevado a cabo el paso de la ejecución de la instrucción. Durante este paso, varias unidades del CPU son conectadas de tal manera que ellas pueden realizar la operación deseada. Si, por ejemplo, una operación de adición fue solicitada, una
Unidad aritmético lógica (ALU) será conectada a un conjunto de entradas y un conjunto de salidas. Las entradas proporcionan los números a ser sumados, y las salidas contendrán la suma final.
La ALU contiene la circuitería para realizar operaciones simples de aritmética y lógica en las entradas, como adición y operaciones de bits (bitwise). Si la operación de adición produce un resultado demasiado grande para poder ser manejado por el CPU, también puede ser ajustada una bandera (flag) de
Desbordamiento aritmético localizada en un registro de banderas (ver abajo la sección sobre rango de números enteros).
El paso final, la escritura (writeback), simplemente "escribe" los resultados del paso de ejecución a una cierta forma de memoria. Muy a menudo, los resultados son escritos a algún registro interno del CPU para acceso rápido por subsecuentes instrucciones. En otros casos los resultados pueden ser escritos a una
memoria principal más lenta pero más barata y más grande. Algunos tipos de instrucciones manipulan el contador de programa en lugar de directamente producir datos de resultado.
Éstas son llamadas generalmente "saltos" (jumps) y facilitan comportamientos como
Bucles (loops), la ejecución condicional de programas (con el uso de saltos condicionales), y
funciones en programas. Muchas instrucciones también cambiarán el estado de dígitos en un registro de "banderas". Estas banderas pueden ser usadas para influenciar cómo se comporta un programa, puesto que a menudo indican el resultado de varias operaciones. Por ejemplo, un tipo de instrucción de "comparación" considera dos valores y fija un número, en el registro de banderas, de acuerdo a cuál es el mayor. Entonces, esta bandera puede ser usada por una posterior instrucción de salto para determinar el flujo de programa.
Después de la ejecución de la instrucción y la escritura de los datos resultantes, el proceso entero se repite con el siguiente ciclo de instrucción, normalmente leyendo la siguiente instrucción en secuencia debido al valor incrementado en el contador de programa. Si la instrucción completada era un salto, el contador de programa será modificado para contener la dirección de la instrucción a la cual se saltó, y la ejecución del programa continúa normalmente. En CPUs más complejos que el descrito aquí, múltiples instrucciones pueden ser leídas, decodificadas, y ejecutadas simultáneamente. Esta sección describe lo que es referido generalmente como el "entubado RISC clásico" (Classic RISC pipeline), que de hecho es bastante común entre los CPU simples usados en muchos dispositivos electrónicos, a menudo llamados
Microcontroladores.








.jpg)

.jpg)